
Cet article aborde l’utilisation des expressions régulières en C# .NET (couramment appelées Regex pour Regular expressions). Le principe des expressions régulières, c’est de rechercher un motif particulier dans un texte pour l’exploiter ensuite.
Par exemple, l’emploi d’une Regex permet de vérifier si un énoncé contient des chiffres, et si oui les additionner. Ou alors, vérifier si un texte saisi par un utilisateur contient que des caractères autorisés et enlever les caractères non autorisés de la chaîne. Ou encore détecter les éléments d’une adresse postale (rue, code postal, ville) pour les récupérer dans des champs séparés.
Après une brève explication sur l’écriture des Regex, nous aborderons la manière dont elles sont utilisables dans un programme développé en C# .NET.
Dans cet article
Construire un motif de Regex
Pour mettre un pied dans les expressions régulières, commençons par quelques exemples avant de détailler ce qui constitue un motif.
Voici quelques exemples de motifs d’expressions régulières :
| Motif | Correspondances |
|---|---|
| codeclub | codeclub |
| rouge|bleu | rouge, bleu |
| gr[aièo]s | gras, gris, grès, gros |
| con(fond|stern)ant | confondant, consternant |
| pa?ris | paris, pris |
| ye*ah | yah, yeah, yeeah, yeeeah, yeeeeah… |
| ye+ah | yeah, yeeah, yeeeah, yeeeeah… |
| ta(rata)+ta | taratata, tarataratata, raratarataratata… |
| \d | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 |
| \d{5} | code postal français (5 chiffres entre 0 et 9) |
| [2-9]|[12]\d|3[0-6] | entier de 2 à 36 inclus |
| [IVXCDLM]+ | chiffres romains (I, II, III, IV, V, VI, VIII…) ou toute autre chaîne comprenant ces caractères (DICI, VIXI, MIC…) |
| pré..dent | chaîne commençant par pré, finissant par dent, et contenant 2 caractères entre les deux. « président » et « précédent » correspondent, mais aussi « pré12dent » |
| [^j*3@] | caractère autre que j, une asterisque, le chiffre 3 ou un arobase |
| \w{3,8} | n’importe quel mot entre 3 et 8 lettres |
| ^club | commence par « club » |
| club$ | finit par « club » |
| ^club$ | est exactement « club » |
Ces quelques exemples montrent des cas qui peuvent être utilisés couramment, mais tout l’intérêt, c’est de pouvoir construire sa propre Regex. C’est pourquoi nous allons détailler comment est construit un motif de Regex.
Composants de base d’une expression régulière
Pour construire un motif, vous allez utiliser différents symboles précis, définissant le caractère que vous cherchez, et en quelle quantité.
- [a-z] correspond à n’importe quelle lettre minuscule de a à z.
- [2-6] symbolise n’importe quel chiffre de 2 à 6.
- [AEIOUY] correspond à n’importe laquelle des lettres indiquées entre crochets (donc n’importe quelle voyelle, du moment qu’elle est en majuscule).
- motif , sans crochets, ne va correspondre qu’à cette série de caractères, dans cet ordre-là. Donc on aura un match sur « motif » mais pas sur « foitm » ni sur « Motif » ou « m otif ».
- \w correspond à n’importe quel caractère de mot (w comme word), donc tout caractère alphanumérique. Attention, cela ne reconnaît pas les caractères accentués en français !
- \d correspond à n’importe quel chiffre (d comme digit).
- \s correspond à tout caractère d’espacement (s comme space) : un espace, une tabulation.
- . (un simple point) correspond à n’importe quel caractère, sauf celui qui symbolise une nouvelle ligne (\n).
Une expression de ce type va correspondre à une seule occurrence de ce qui est entre crochets, sauf si elle est suivi d’un quantificateur.
- a* : 0 fois la lettre a ou plus.
- a+ : 1 fois la lettre a ou plus.
- a? : 0 ou 1 fois la lettre a.
- a{6} : exactement 6 fois la lettre a
- a{1,3} : 1 à 3 fois la lettre a
- a{4,} : 4 fois ou plus la lettre a
Les quantificateurs * et ? nous permettent de traiter le cas où un caractère n’est pas trouvé. À l’inverse, le quantificateur + et ceux avec des chiffres entre accolades permettent de s’assurer que le caractère est présent au moins une fois (ou n fois).
D’autres éléments permettent de préciser un motif :
L’accent circonflexe ^ inverse la correspondance. Si après l’ouverture de crochets, vous ajoutez un ^, la correspondance sera avec tout ce qui n’est pas indiqué dans les crochets. Par exemple : [^AEIOUyaeiouy] matche avec toutes les consonnes, mais aussi avec tous les chiffres, caractères spéciaux, espaces…
La barre verticale | (Alt Gr + 6) est utilisée comme « ou » : la correspondance se fera avec l’expression avant ou après le | . Par exemple rouge|vert|bleu correspond à une seule de ces trois expressions. L’expression [IVXCDLM]+|\d+ permet de trouver les chiffres exprimés en chiffres romains en plus des caractères classiques de chiffres (0, 1, 2, 3…).
Enfin, ^ et $ sont des caractères qui délimitent le début et la fin d’une chaîne (^ pour le début, $ pour la fin). Par exemple, ^[A-Z]
Tous les caractères peuvent être échappés (via le caractère \) afin de pouvoir les utiliser dans les expressions. Par exemple, l’expression \[\w+\] correspond à toutes les expressions qui contiendront un mot de 1 lettre ou plus entre crochets.
Le principe des groupes de capture et des groupes de non-capture
En rédigeant notre expression régulière, nous allons avoir la possibilité de définir quelle partie des correspondances nous souhaitons récupérer. Les parenthèses nous permettent ainsi de définir des groupes de capture dans notre expression. Cela permet de récupérer juste un partie des correspondances obtenues.
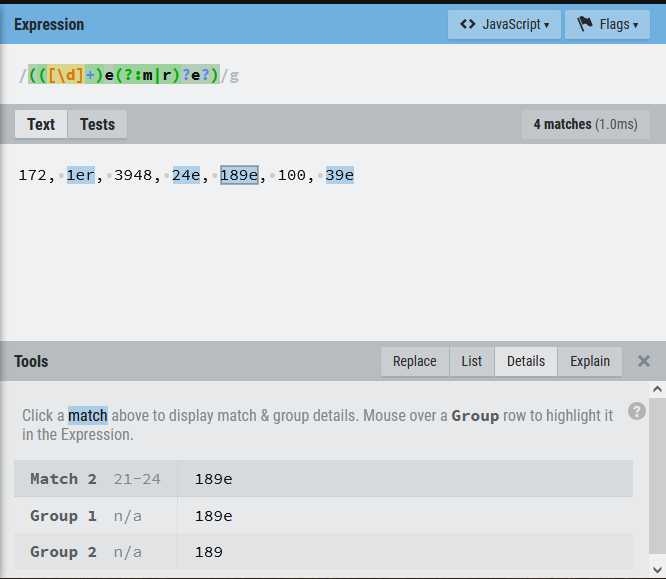
Pour illustrer la différence entre groupe de capture et correspondances, prenons un exemple nous avons un texte qui contient différents chiffres, certains sont des ordinaux (1er, 2e, 42e…), et d’autres étant des cardinaux (1, 2, 7, 10, 20…). Nous voulons récupérer uniquement les ordinaux, et uniquement la partie chiffre.
Nous utiliserons l’expression régulière ([\d]+)em?r?e? : les parenthèses servent à capturer 1 ou plusieurs chiffres, et les em?r?e? permettent de correspondre avec e, em, eme, er, ere, et même emre et ee.
- Pour la chaîne en entrée : 172, 1er, 3948, 24e, 189e, 100, 39e
- Nos correspondances (matches) sont : 1er, 24e, 189e, 39e
- Nos groupes de captures (group) sont : 1, 24, 189, 39.
Bien sûr, les autres chiffres (172, 3948, 100) ne correspondent pas au schéma, donc ils sont ignorés.
Les parenthèses permettent aussi de grouper les éléments vus ci-dessus, sans pour autant les capturer. Pour éviter considérer des éléments groupés ensemble comme des groupes de capture, il faut commencer la parenthèse du groupe par les symboles (?: .
Pour reprendre notre format ci-dessus, en remplaçant le motif ([\d]+)e(?:m|r)?e? , nous avons :
- Un premier groupe, ([\d]+) groupe de capture de 1 chiffre ou plus
- Un second groupe (?:m|r) qui est un groupe de non-capture, il correspond à m OU r.
Comme le second groupe est suivi par un point d’interrogation ?, il est facultatif (0 ou 1). Ainsi, pour avoir une correspondance, il nous faut avoir 1 chiffre ou plus, suivi de la lettre e, et optionnellement les autres lettres. Là, le schéma ne correspond plus avec « emre » comme c’était le cas plus haut,
Une correspondance peut avoir plusieurs groupes de capture, avec des parenthèses lestées et/ou côte à côte. Par exemple, si notre motif est (([\d]+)(e(?:m|r)?e?)) :
- La correspondance sera sur les chiffres au format 189eme
- Groupe de capture 1 : la parenthèse qui entoure l’ensemble (189eme)
- Groupe de capture 2 : la parenthèse sur la partie de gauche (189)
- Groupe de capture 3 : la parenthèse sur la partie de droite (eme)
Conseil : prenez la bonne habitude de capturer seulement ce dont vous avez besoin précisément, et d’utiliser les groupes de non-capture pour le reste.
Pour aller plus loin dans la construction des Regex
Dans la suite de l’article, nous allons aborder la spécificité des expressions régulières dans un logiciel C# .NET, mais c’est typiquement une compétence très transversale, qui peut vous être utile dans de nombreux
Les outils de bureautique ou les éditeurs multi-langages comme Notepad++ ou Visual Studio / Code disposent généralement d’une option pour les expression régulières dans leur interface Rechercher/Remplacer, ce qui permet de modifier ou rechercher très vite un motif donné dans un texte.
De même, les tableurs (Excel, Calc, Spreadsheets) ont des fonction vous permettant d’exploiter les expressions régulières dans les formules de calcul (de type SUMIF, COUNTIF, MATCH, SEARCH, LOOKUP…), qui vous permettent de récupérer automatiquement des données exploitables selon les motifs voulus.
Le meilleur conseil que je puisse vous donner pour travailler sur vos Regex, c’est d’utiliser un outil en ligne pour construire et travailler vos expressions. Le très pédagogique RegExr vous permet de créer votre Regex en temps réel, avec le texte de votre choix, et présente de manière très visuelle ce qui est capturé, et vous fournit un paquet d’informations sur votre Regex. Par exemple, vous pouvez avoir le détail de chaque symbole, mais aussi avoir la distinction entre la correspondance (Match) et le groupe de capture (Group).
Expression régulières en C# : mode d’emploi
Avant toute chose, n’oubliez pas que l’expression régulière n’est parfois pas le choix le plus judicieux : dans beaucoup de cas courant, vous pouvez remplacer un élément précis dans une chaîne via string.Replace().
Un exemple : si nous importons du texte dans le programme et que le code [Username] est à remplacer par le nom de l’utilisateur, string.Replace() fera parfaitement l’affaire. De même, si vous cherchez un mot en particulier, string.Contains(string mot) fera parfaitement l’affaire. Voir le guide sur les chaînes de caractère en C# pour plus d’exemples.
L’expression régulière est typiquement utile dans le cas où vous cherchez un motif précis, sans savoir exactement la teneur des données vous allez recevoir.
Le namespace RegularExpressions et ses classes
L’espace de nom dédié du C# .NET pour les expressions régulières est System.Text.RegularExpressions. Aussi, nous devons l’appeler au début du script qui l’utilise :
using System.Text.RegularExpressions;Il nous donne accès aux classes suivantes :
- Regex : la construction d’une expression régulière immuable et les méthodes permettant d’obtenir des objets Match / MatchCollection
- Match et MatchCollection : la représentation d’une correspondance ou de plusieurs correspondances d’expressions régulières dans un texte.
- Group et GroupCollection : la représentation d’un groupe de captures ou d’un ensemble de groupes de capture (au sein d’une correspondance)
- Capture et CaptureCollection : la représentation d’une capture ou d’une collection de Captures successives (au sein d’un groupe de captures)
L’utilisation d’une expression régulière en C# .NET, c’est :
- Construire notre motif d’expression régulière (un objet Regex). Une chaîne exprimant une expression régulière est précédée par le caractère @ (identificateur de chaîne textuelle).
- Appliquer la méthode « Match » de cet objet Regex sur la chaîne où on cherche ce motif pour obtenir un objet Match.
- Vérifier s’il y a une correspondance avec Match.success (et utiliser les méthodes de l’objet Match que nous avons créé).
string Haystack = "lpbtecqiajeqfbdsjksdwofkxrhlwnfgpxdpsnvgneedletgroqsuaeinqfjcdvtewddnnibzneedlezloyxtaetnxia";
// Haystack est notre botte de foin.
Regex needleRegex = new Regex(@"needle");
Match needleMatch = needleRegex.Match(Haystack);
if(needleMatch.Success)
{
Console.WriteLine($"Aiguille trouvée dans la botte de foin.");
while (needleMatch.Success)
{
Console.WriteLine($"Terme '{needleMatch.Value}' trouvé à la position {needleMatch.Index}.");
needleMatch = needleMatch.NextMatch();
}
}
// Sortie console :
// Aiguille trouvée dans la botte de foin.
// Terme 'needle' trouvé à la position 40.
// Terme 'needle' trouvé à la position 73.Après avoir défini notre Regex needleRegex, nous utilisons donc sa méthode Match() sur notre chaîne de caractère pour récupérer des correspondances dans un objet Match.
Notre objet needleMatch va donc nous indiquer avec la propriété Success si nous avons bien une correspondance. À partir de là, nous pouvons lire la position de la correspondance, récupérer la valeur trouvée, et passer à la correspondance suivante avec NextMatch.
Une autre approche, c’est d’utiliser la méthode Matches() de notre objet Regex. Il y a une différence subtile : là où Regex.Match() nous envoie une seule correspondance Match et nous permet de naviguer vers la suivante, la méthode Regex.Matches() nous permet d’obtenir une collection de correspondances, et donc d’avoir directement le compte et l’accès à la N-ième correspondance.
MatchCollection needleMatches = needleRegex.Matches(Haystack);
if (needleMatches.Count > 0)
{
Console.WriteLine($"Aiguille trouvée {needleMatches.Count} fois dans la botte de foin. ");
foreach(Match match in needleMatches)
{
Console.WriteLine("Trouvée à la position " + match.Index);
}
}
// Sortie console :
// Aiguille trouvée 2 fois dans la botte de foin.
// Trouvée à la position 40
// Trouvée à la position 73Comme nous obtenons directement une collection de correspondances, nous avons le nombre de correspondances (MatchCollection.Count)
Sélection de méthodes de Regex (expression régulière)
| Méthode | Retour | Description |
|---|---|---|
| Match(Texte) | Objet Match | Obtenir une correspondance dans Texte |
| Matches(Texte) | Objet MatchCollection | Obtenir une collection de correspondances dans Texte |
| IsMatch(Texte) | Booléen (true ou false) | Indique s’il y a au moins une correspondance dans le Texte |
| Split(Texte) | string[] (tableau de chaînes) | Permet de récupérer les correspondances dans un tableau de chaînes de caractères |
| ToString(Texte) | Chaîne de caractère | Retourne l’expression régulière passée |
À noter que ces méthodes (mise à part ToString) peuvent être aussi utilisées directement en tant méthodes statiques, sans avoir à créer d’instance de Regex. Il suffit d’utiliser comme premier paramètre la chaîne dans laquelle on cherche, et en second paramètre notre expression régulière.
Match needleMatch = Regex.Match(Haystack, @"needle");
Matches needleMatches = Regex.Matches(Haystack, @"needle");C’est utile lorsqu’on utilise une expression régulière une seule et unique fois, et ça dépendra bien sûr de la conception de votre logiciel.
Sélection de méthodes et de propriétés de Match (correspondance unique)
Après avoir récupéré votre correspondance dans un objet Match, les propriétés suivantes sont utilisables :
| Méthode | Retour | Description |
|---|---|---|
| Success | Booléen (true ou false) | Indique si l’objet contient une correspondance |
| NextMatch() | Objet Match | Passe à la correspondance suivante. S’il n’y a plus de correspondance, l’Objet Match obtenu aura la propriété Success = false. |
| Value | string, chaîne de caractère | Valeur capturée au niveau de la correspondance |
| Length | int, entier | Longueur de la valeur de correspondance |
| Index | int, entier | Position du premier caractère de la correspondance |
| Groups | Objet GroupCollections | Collection (pouvant être vide) de tous les groupes de captures obtenus lors de la correspondance. |
| Captures | Objet CaptureCollections | Collection (pouvant être vide) de tous les groupes de captures obtenus lors de la correspondance. |
Match hérite de plusieurs classes, certaines méthodes ou propriété viennent de cet héritage.
Capturer une ou plusieurs expressions dans une correspondance (groupes de captures)
Comme nous l’avons vu, les objets Match et MatchCollection, qui indiquent les correspondances, permettent directement de récupérer les endroits qui correspondent à notre motif. Ça permet dans de nombreux cas de vérifier si notre motif existe dans la chaîne de caractères.
Cependant, nous avons parfois besoin d’une partie explicitement définie de notre chaîne de caractère. C’est là que les groupes de captures entrent en jeu.
Groupes de Capture, classes Group et GroupCollections
Nous allons travailler sur cet extrait de Vingt Mille Lieues sous les mers, stocké ci-après dans la variable textFromBook.
Quinze jours plus tard, à deux mille lieues de là, l’Helvetia, de la Compagnie Nationale, et le Shannon, du Royal-Mail, marchant à contrebord dans cette portion de l’Atlantique comprise entre les États-Unis et l’Europe, se signalèrent respectivement le monstre par 42°15′ de latitude nord, et 60°35′ de longitude à l’ouest du méridien de Greenwich.
Jules Verne, Vingt Mille Lieues sous les mers
Comme nous l’avons vu dans la première section, un groupe de capture est défini par des parenthèses simples. Ici, nous allons extraire les coordonnées pour les présenter différemment.
Notre motif va être le suivant : ((\d\d)°(\d\d)') de (\w+)
Vous pouvez y voir quatre groupe de captures (de l’extérieur vers l’intérieur, et de gauche à droite) :
- L’un englobe la coordonnée au format (xx°xx’)
- Le deuxième entoure uniquement le début de la coordonnée, les degrés (avant °)
- Le troisième entoure la deuxième moitié de la coordonnée, les minutes (avant ‘)
- Le quatrième englobe le mot qui suit les coordonnées et le mot « de ». Avec le texte, ça sera soit « longitude » et « latitude » (pour simplifier, nous ne préciserons pas que c’est une latitude nord et une longitude ouest).
Nous allons récupérer un objet MatchCollection via Regex.Matches(), puis boucler sur les Match de cette collection pour explorer chacune de ces correspondances.
Dans chaque correspondance match, nous allons récupérer l’objet match.Groups, correspondant aux groupes de captures. Dans un premier temps, contentons-nous d’afficher le contenu de ces groupes :
string coordinatesPattern = @"((\d\d)°(\d\d)') de (\w+)";
foreach(Match match in Regex.Matches(textFromBook, coordinatesPattern))
{
for(int i = 0; i < match.Groups.Count; i++)
{
Console.WriteLine($"{i} : {match.Groups[i]}");
}
}
// Sortie console (pour le premier match) :
// 0 : 42°15' de latitude
// 1 : 42°15'
// 2 : 42
// 3 : 15
// 4 : latitudeIci, nous obtenons effectivement les 4 captures décrites plus haut, correspondant aux différentes parenthèses. Sur les indices de 1 à 4, ça correspond trait pour trait à ce qui est décrit plus haut.
Et nous voyons qu’il y a également un indice 0, qui contient non pas un groupe de capture, mais toute la correspondance. C’est une chose à noter : en utilisant la méthode Groups, vous obtenez une collection comprenant la correspondance (indice 0) puis tous les groupes de capture.
Connaissant nos groupes de capture, nous pouvons utiliser chacune des données capturées directement dans la chaîne que nous produisons en sortie, par exemple de cette manière :
string coordinatesPattern = @"((\d\d)°(\d\d)') de (\w+)";
foreach(Match match in Regex.Matches(textFromBook, coordinatesPattern))
{
Console.WriteLine($"{match.Groups[4]} : {match.Groups[2]} degrés {match.Groups[3]} minutes (au format : {match.Groups[1]}).");
}
// Sortie console :
// latitude : 42 degrés 15 minutes (au format : 42°15').
// longitude: 60 degrés 35 minutes (au format : 60°35').Sur le même texte, construisons maintenant un motif permettant d’obtenir tous les noms propres du texte, y compris ceux qui contiennent un espace ou un tiret. Le schéma en question récupérera aussi le déterminant qui précède.
Voici le schéma que nous utilisons :
Regex :(\w*'?) ?(([A-ZÉ])[a-z]*(?:[ -]([A-ZÉ])[a-z]*)?)
| Partie de la regex | Explication |
|---|---|
| (\w*'?) | déterminant précédant le schéma (compatible avec les « l' » et les « d' ». |
| ? | un espace facultatif |
| ( | début du second groupe de capture (tout le lieu, avec 1 ou 2 noms) |
| ([A-ZÉ]) | troisième groupe de capture : la majuscule (incluant É pour les États-Unis) |
| [a-z]* | au moins une lettre suivant la majuscule |
| (?: | début d’un groupe non capturé (deuxième partie du nom, facultative) |
| [ -] | s’il y a une deuxième partie dans le nom, elle doit commencer soit par un espace, soit par un tiret |
| ([A-ZÉ]) | quatrième groupe de capture : la majuscule de la deuxième partie du nom |
| [a-z]* | suite de la deuxième partie du nom : une ou plusieurs lettres après la majuscule |
| )? | fin du groupe non capturé, le « ? » indique que ce groupe est facultatif |
| ) | fin du second groupe de capture (tout le lieu, avec 1 ou 2 noms) |
Une fois ce schéma établi, nous pouvons faciliter son utilisation en donnant un nom aux groupes de capture. Pour donner un nom au groupe de capture, le format est le suivant : (?<nomdugroupe>[A-Z]).
Ainsi, en ajoutant des noms aux groupes de capture ci-dessus, voici comment s’écrit la Regex : (?<previousWord>\w*'?) ?(?<name>(?<firstInitial>[A-ZÉ])[a-z]*(?:[ -](?<secondInitial>[A-ZÉ])[a-z]*)?).
Et voici le code qui exploite cette Regex sur notre texte de Jules Verne, donnant une liste des noms propres évoqués avec leurs initiales :
string locationsPattern = @"(?<previousWord>\w*'?) ?(?<name>(?<firstInitial>[A-ZÉ])[a-z]*(?:[ -](?<secondInitial>[A-ZÉ])[a-z]*)?)";
foreach (Match match in Regex.Matches(textFromBook, locationsPattern))
{
if(match.Groups["previousWord"].Value != string.Empty)
{
string initials = match.Groups["firstInitial"] + "." + (match.Groups["secondInitial"].Value != string.Empty ? (match.Groups["secondInitial"] + ".") : "");
Console.WriteLine($"{match.Groups["name"]} ({match.Groups["previousWord"]}), initiales : {initials}");
}
}
// Sortie console :
// Helvetia (l'), initiales : H.
// Compagnie Nationale (la), initiales : C.N.
// Shannon (le), initiales : S.
// Royal-Mail (du), initiales : R.M.
// Atlantique (l'), initiales : A.
// États-Unis (les), initiales : É.U.
// Europe (l'), initiales : E.
// Greenwich (de), initiales : G.N.B. : si vous avez nommé tous vos groupes de capture, vous pouvez itérer sur ceux-ci pour récupérer les noms et les valeurs, avec une boucle de ce type appelant la propriété Name et Value de chaque groupe :
foreach (Group group in match.Groups)
{
Console.WriteLine($"{group.Name} : {group.Value}");
}Si le groupe de capture n’est pas nommé, c’est simplement son indice qui apparaît.
Récupérer des éléments précis avec des groupes des captures imbriqués et multiples : classes Capture et CapturesCollection
Il existe un dernier niveau de récupération d’information : la classe Captures. C’est un usage que vous rencontrerez probablement moins souvent. Il s’agit de récupérer les éléments individuels des groupes de captures.
Par exemple, si vous utilisez la Regex (([^\s])*) (tout groupe de caractère n’étant pas un espace), vous allez capturer chaque mot puis chaque caractère de chaque mot.
Vous aurez alors l’arborescence suivante :
- Chaque mot est un Match (par ex : Quinze)
- Chaque Match contient deux Groupe de capture : la première est le mot entier (Quinze), la seconde est la dernière capture ressemblant au schéma (avec notre exemple, la dernière lettre du mot). (par ex : e)
- Chaque Groupe de capture contient plusieurs Captures, chacune correspondant aux lettres du mot. (en itérant sur group.Captures, on obtient : Q, u, i, n, z et e)
- Chaque Match contient deux Groupe de capture : la première est le mot entier (Quinze), la seconde est la dernière capture ressemblant au schéma (avec notre exemple, la dernière lettre du mot). (par ex : e)

Vous pouvez explorer votre arborescence de correspondances et groupes de captures avec des boucles foreach imbriquées.
foreach (Match match in Regex.Matches(textFromBook, pattern)) // Regex.Matches est une MatchCollection
{
foreach (Group group in match.Groups) // match.Groups est une GroupCollection
{
foreach (Capture capture in group.Captures) // group.Captures est une CaptureCollection
{
Console.WriteLine($">>> Match {match} > Group {group} > Capture {capture} ");
}
}
}J’espère que cette introduction à l’utilisation des expressions régulières vous aura apporté, si nécessaire, une compréhension de leur utilité et de la manière de les utiliser dans une application C#.
One thought on “Utiliser des expressions régulières en C# .NET”
Commentaires désactivés